在容器化与多租户成为常态的今天,GPU 既是价值最高的计算资源,也是最难被精细化管理的资源。传统的独占模式在成本与效率上已经难以满足需求,工程上迫切需要一种能被 Kubernetes 调度、能被容器边界限制、能被监控与回收的 GPU 虚拟化方案。gpu-manager 正是在这一背景下出现的:它以 device plugin 的方式接入 kubelet,以 vGPU 方式细分资源,并通过 CUDA 调用拦截在运行时实施限制与监控。
本文以 gpu-manager 的启动流程为主线,在原文解析的基础上补充调度策略、拓扑感知、运维治理、风险边界等关键工程细节,形成一篇面向落地的长文综述,供 GPU 平台与 Kubernetes 运维团队参考。
一、GPU 虚拟化为何必须"工程化"
GPU 与 CPU 的最大差异不在算力规模,而在使用模型:CPU 天然支持进程间隔离和调度,而 GPU 对用户态与驱动栈依赖极强,且对资源隔离的原生支持有限。导致在容器环境中,GPU 的管理往往停留在"硬件独占"的阶段。它带来的问题包括:
- 资源浪费:许多推理任务的显存与算力占用极小,却必须占用整张卡。
- 租户冲突:多用户共享时无法限制 GPU 使用,容易出现抢占或资源挤压。
- 调度粗糙:Kubernetes 无法理解 GPU 的"部分资源",只能做整卡调度。
- 运维复杂:驱动升级或库冲突容易导致全局故障。
GPU 资源的切分可以从两个维度来理解。空间维度上,一次调度上 GPU 运行的任务并不能充分利用全部 GPU 资源——许多核心处于空闲状态,GPU 的饱和度利用不高。时间维度上,多个任务交替运行存在切换和等待开销,为了保障 SLA,延迟敏感的高优业务往往不得不独占整卡,利用率进一步下降。为提升 GPU 资源利用率,空分方案着眼于在同一时刻让多个任务并行运行,以填充空闲算力;时分方案则通过控制时间片来减少任务切换的等待开销,利用弹性特质更好地复用空闲资源。
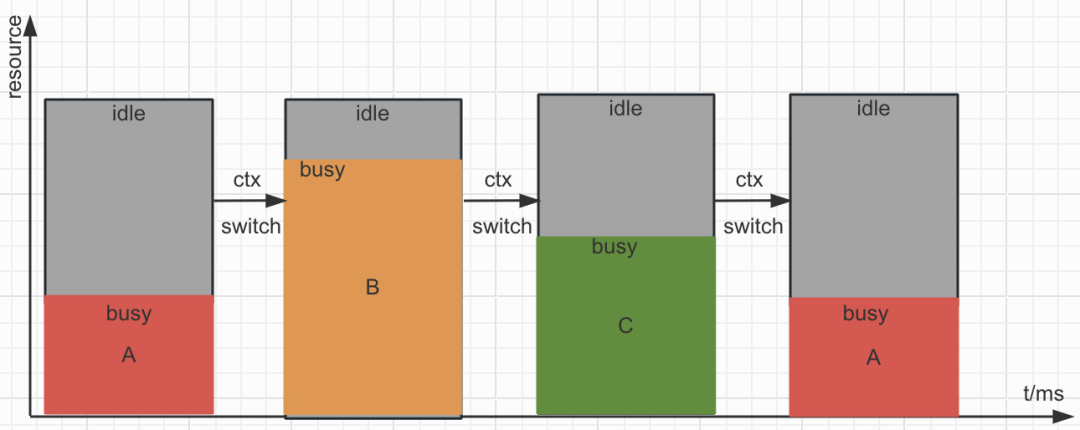
gpu-manager 的方案试图回答三个工程问题:
- 资源如何拆分:将 GPU 资源抽象为计算能力与显存两个维度;
- 拆分后的资源如何实施限制:通过拦截 CUDA 调用实现可控的虚拟化层;
- 如何进行更优调度:通过拓扑感知减少跨 NUMA 与跨 PCIe 的性能损耗。
这三点合在一起,构成了"工程化 GPU 虚拟化"的完整路径。
二、CUDA 计算软件栈
理解 GPU 隔离方案的实现原理,需要先掌握资源分配过程涉及的软件栈。
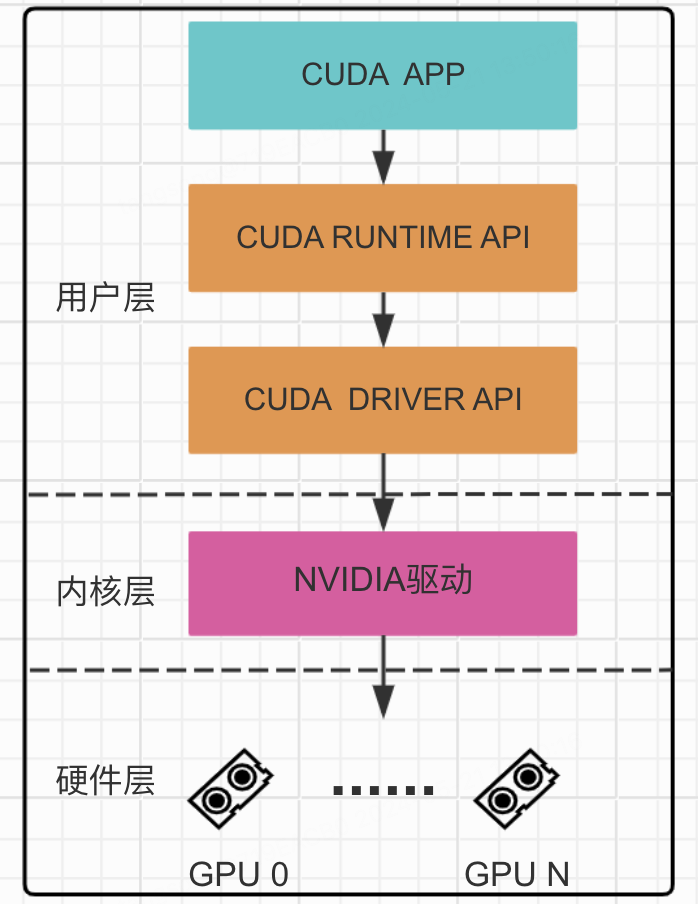
CUDA 计算软件栈从顶层到底层包括四个层次:
- 应用程序:用户编写的 CUDA 程序,调用 CUDA API;
- CUDA 库:分为两层——CUDA Runtime API(higher-level 抽象层,通过
cudart动态库提供,入口点以cuda为前缀)和 CUDA Driver API(low-level 层,通过cuda动态库提供,入口点以cu为前缀,提供对上下文和模块加载的更精细控制); - 内核驱动:NVIDIA GPU 驱动程序,负责管理 GPU 资源、处理与操作系统的交互;
- GPU 硬件:提供并行计算能力的物理设备。
从 API 库到最终硬件,每个阶段的转发都有被拦截的可能性。业界正是基于这个软件栈,在不同层次上实现了各式各样的 GPU 隔离共享方案。
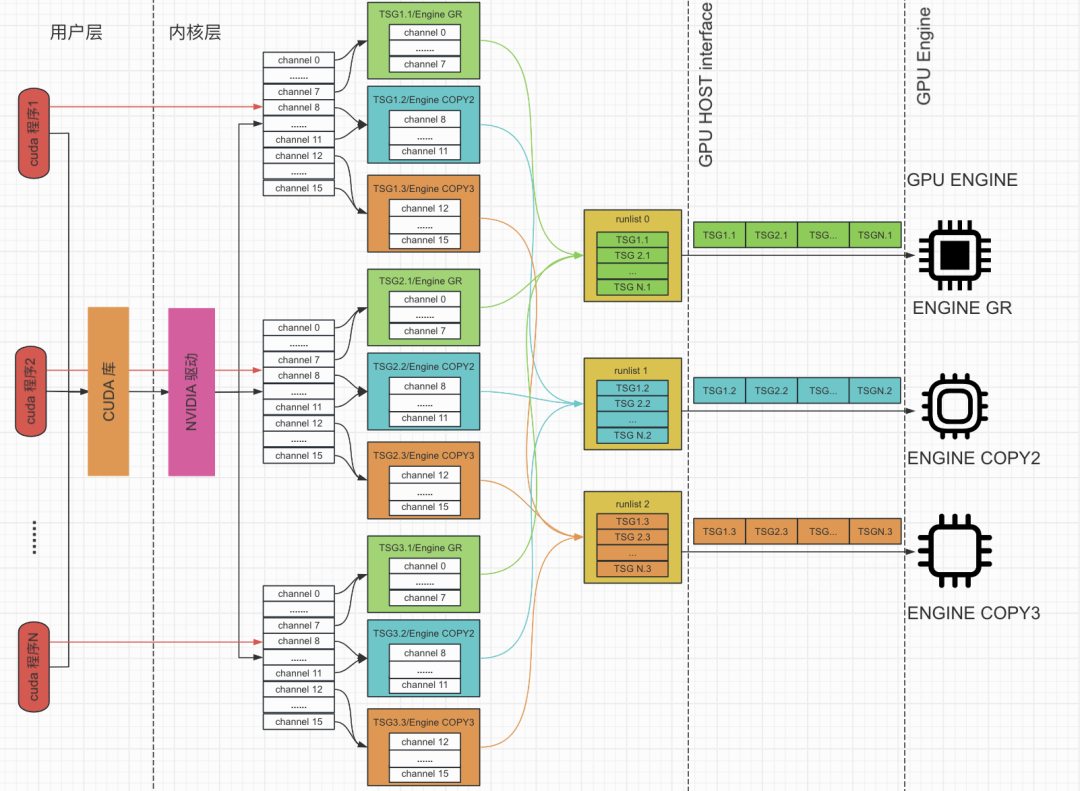
三、GPU 驱动层的调度机制
CUDA 程序提交到 GPU 执行的过程,在驱动层有更细粒度的调度机制。从驱动视角看,GPU 内部由多个功能单元组成(在驱动中称为 Engine),主要包含:
- Compute/Graphics Engine:包含通用计算核心,负责 CUDA 计算和图形渲染;
- Copy Engine:专门处理 GPU 与 CPU 之间的异步数据拷贝;
- NVENC/NVDEC Engine:用于视频编解码等特定任务。
GPU Host 是 CPU 与 GPU 之间的桥梁,由 runlist processor 和 context switcher 组成。runlist processor 负责扫描 runlist、选择下一个待运行的 channel;若新 channel 的 context 与当前正在运行的不同,则由 context switcher 执行上下文切换。
具体调度流程如下:
- 驱动为每个程序创建一个或多个 channels,用于提交计算或数据拷贝请求;
- 这些 channels 被组织到 TSG(Time Slice Group)中,同一 TSG 内的 channels 共享相同的 GPU context 信息;
- TSG 根据分配的 Engine type 找到对应的 runlist;
- GPU Host 识别到有待处理命令的 channel 后,从 runlist 上按时间片轮转摘取一个 TSG,再从该 TSG 中选出 channel,调度到特定 Engine 上执行;
- Engine 执行 channel 中提交的命令,完成计算或数据拷贝。
以 A10 卡上的典型 CUDA 程序为例,trace 结果显示默认会创建 16 个 channels、3 个 TSG 和 3 个 runlist:8 个计算 channels 归入一个 TSG(分配 Compute/Graphics Engine),8 个数据拷贝 channels 分别归入两个 TSG(对应两种 COPY Engine)。每种 Engine 绑定到一个 runlist。
runlist 中每个条目(即 TSG)一次调度默认最多可执行的时间称为 Timeslice。以 runlist0 上的 TSG 为例,时间片为 2ms——即一个 TSG 调度到 Compute/Graphics Engine 上默认最多运行 2ms。只有用完时间片或在时间片内执行完毕,TSG 之间才会发生调度切换。因此在多任务混跑时,TSG 切换和上下文切换是影响延迟的主要因素。
四、业界 GPU 隔离共享方案
目前空分方案以 NVIDIA 官方提供的 MPS 和 MIG 为主,时分方案以 CUDA 劫持和内核拦截为主。
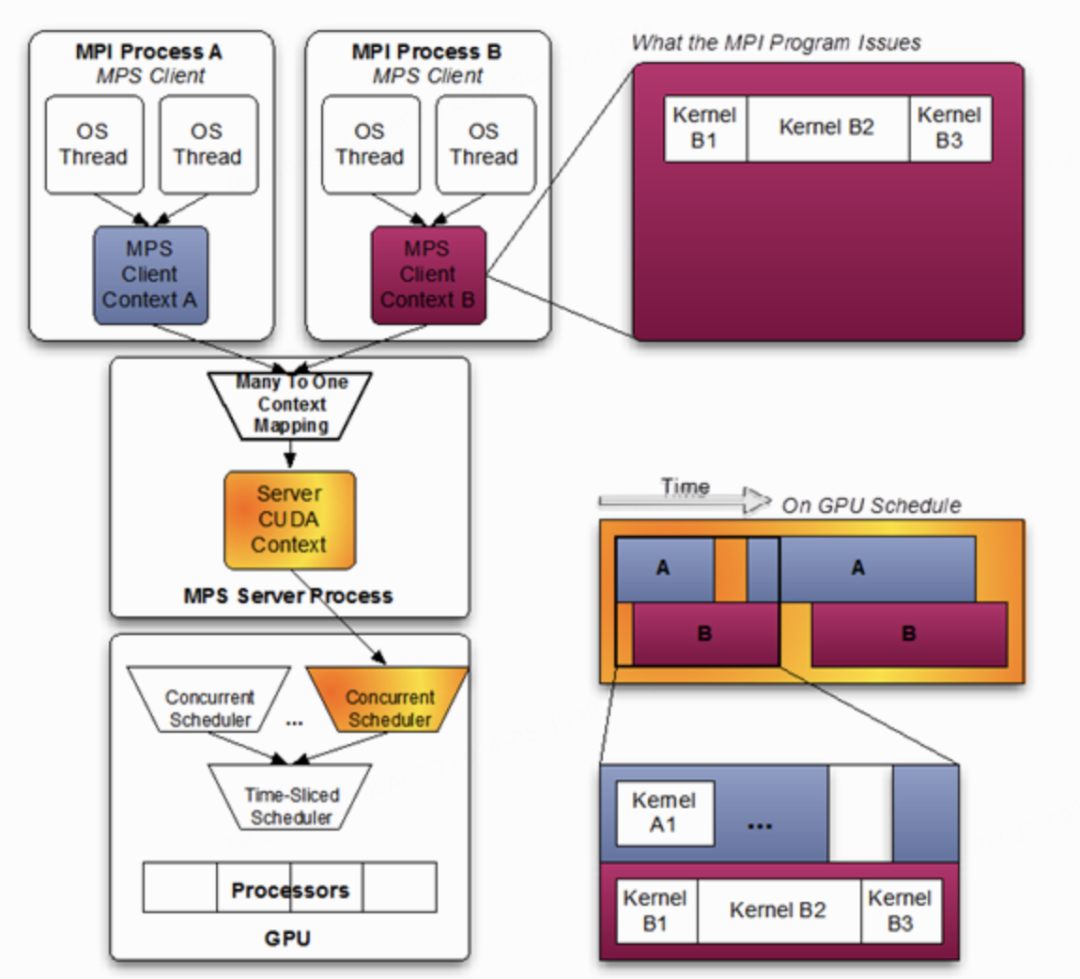
3.1 MPS
通常 GPU 上执行多任务时采用"单任务"工作模式,同一时刻只有一个 context 在 GPU 上执行。MPS 通过将多个任务的 CUDA context 整合到同一个 context,使这些任务共享 GPU 算力与显存。但由于 context 整合后一个任务失败会波及其他任务,存在故障传播问题,且黑盒逻辑使得故障诊断困难。
3.2 MIG
自 NVIDIA A100 系列引入的 MIG 实现了硬件级空间分割与隔离,允许将单个 GPU 分割为多个独立实例,每个实例拥有独立的资源配额。但其局限性在于:仅高端 GPU 支持,最多 7 个实例,资源切分是静态的,运行时无法调整。
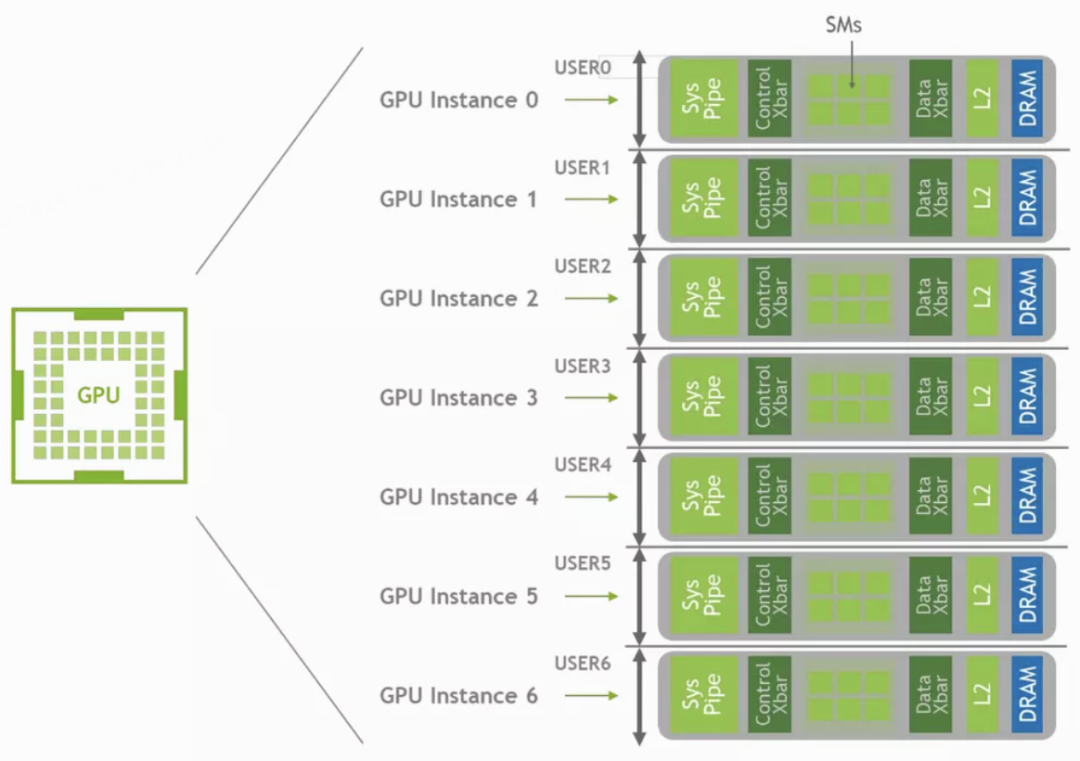
3.3 CUDA 劫持
CUDA 劫持发生在 CUDA Runtime 与 Driver API 之间,通过劫持对 Driver API 的调用来实现资源隔离。典型代表如腾讯早期 GaiaGPU 方案。它在 launch kernel 时评估内核发射对 GPU 使用率的影响,超标则推迟下发。由于 API 功能公开,劫持特定调用可以简单地拒绝或延后资源申请,但存在两个问题:算力消耗缺乏反馈机制(依赖轮询造成浪费),申请下发后失去控制权(容易超配额引入误差)。
3.4 内核拦截
内核拦截发生在 CUDA Driver API 与 NVIDIA 驱动之间,腾讯 qGPU、阿里 cGPU、百度 GPU 隔离方案均属此类。其核心做法是提供假的设备文件(如 /dev/gpu0),APP 调用时进入拦截驱动,解析和修改访问参数后再转发给真实驱动。该方案需要深入理解 CUDA 与 GPU 的交互方式,但交互行为本身是黑盒,版本迭代后可能失效,维护成本较高。
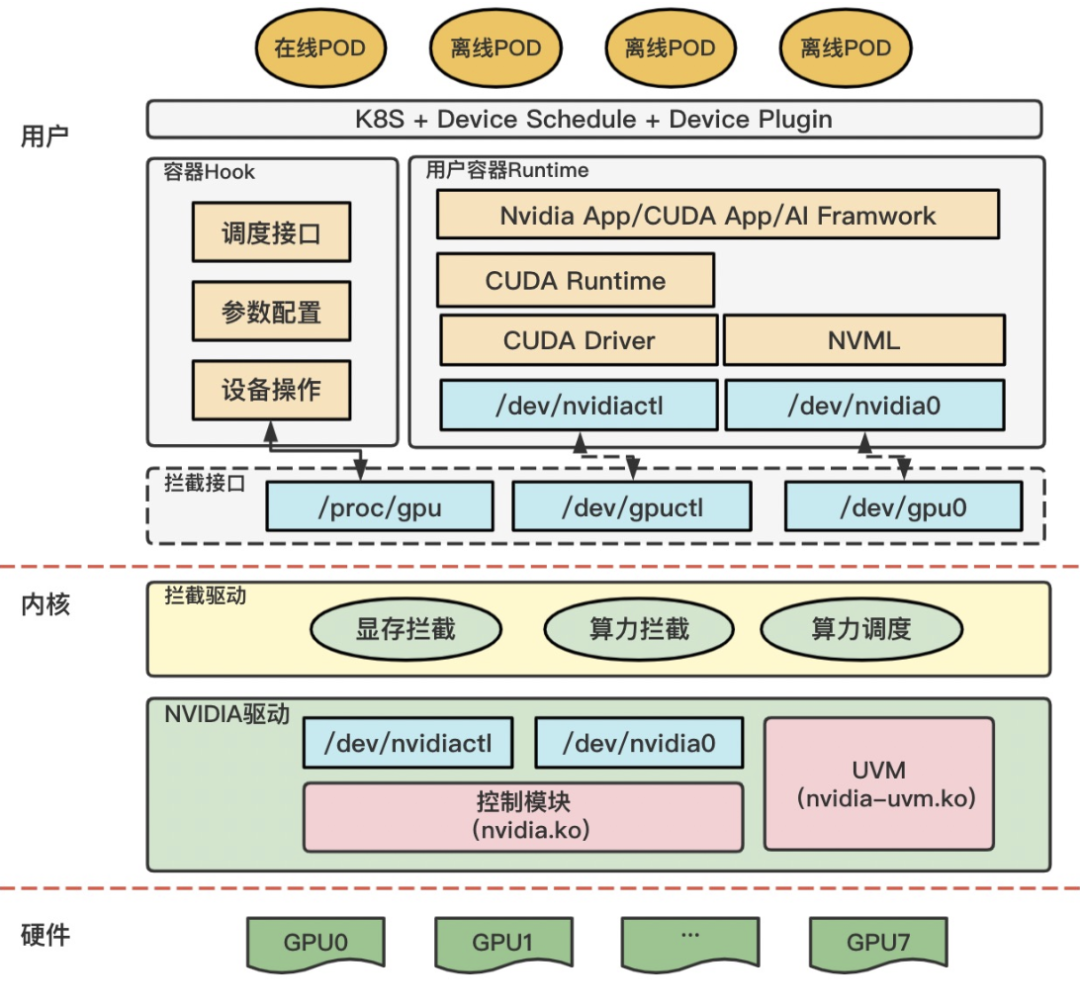
这三种方案(MPS/MIG/CUDA 劫持/内核拦截)与 gpu-manager 的软件层拦截并不冲突,而是不同层级的补充。工程选择上,若硬件支持 MIG 且追求强隔离可优先使用 MIG;若主要是推理并发可考虑 MPS;若硬件多样、存量多、需要统一调度,gpu-manager 的适用性更强。
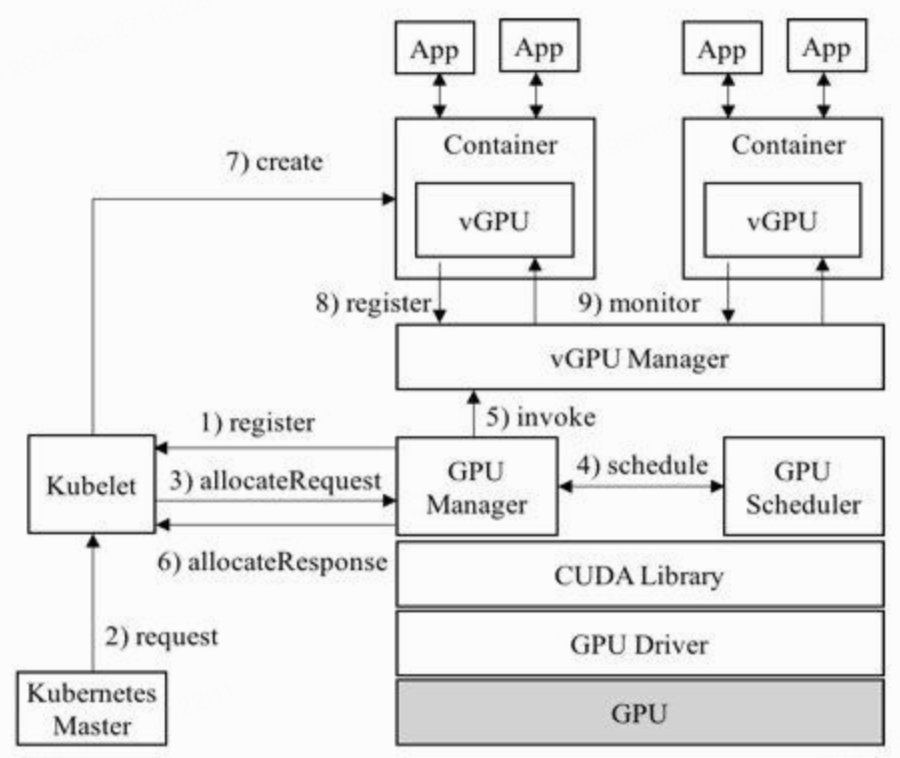
五、Gaia Scheduler 体系中的 gpu-manager 角色
在 Gaia Scheduler 的体系里,gpu-manager 并不是孤立的工具,而是整个 GPU 虚拟化调度体系的核心组件。其相关组件与职责如下:
- GPU Manager:对 kubelet 注册 GPU 资源,负责与 device plugin 机制交互;
- GPU Scheduler:负责在节点内部做最优的 GPU 资源分配决策;
- vGPU Manager:管理容器级别的 vGPU 运行状态、回收、通信;
- vGPU Library:通过
libcuda-control.so拦截 CUDA API 调用,是虚拟化核心。
gpu-manager 项目集成了 GPU Manager 与 vGPU Library 的关键能力,最终实现"无需特殊硬件支持"的 GPU 虚拟化。这一点在工程落地中非常重要,因为大量存量 GPU 并不支持硬件级切割(如 MIG),而软件层的拦截机制可以在更广泛的环境中部署。
六、device plugin:让 GPU 成为 Kubernetes 可调度资源
Kubernetes 原生并不理解 GPU。device plugin 机制是它扩展资源类型的关键接口。gpu-manager 以该机制注册两类资源:
tencent.com/vcuda-core:代表计算资源(核心维度);tencent.com/vcuda-memory:代表显存资源(内存维度)。
这意味着调度器可以在 Pod 的 resources.requests 中显式请求 GPU 的"部分资源",而不再只请求"整张卡"。gpu-manager 通过 Allocate 方法把实际设备或虚拟设备注入容器,并配合 vGPU Library 实施运行时限制。
从工程角度看,这一设计的意义在于:
- 让 GPU 资源成为"声明式资源";
- 支持调度器进行精细化匹配;
- 为后续监控、回收、治理提供结构化入口。
下面是一个最小化的资源申请示例,展示如何在 Pod 中声明 vcuda 资源:
apiVersion: v1
kind: Pod
metadata:
name: demo-vcuda
spec:
containers:
- name: demo
image: nvidia/cuda:12.2.0-base
resources:
requests:
tencent.com/vcuda-core: "20"
tencent.com/vcuda-memory: "8Gi"
limits:
tencent.com/vcuda-core: "20"
tencent.com/vcuda-memory: "8Gi"
七、启动参数:从配置理解行为边界
gpu-manager 的启动参数是理解其行为边界的第一把钥匙。以下是关键参数的工程意义解读:
driver:驱动类型,默认 nvidia,决定驱动拦截的具体策略。extra-config:扩展配置入口,通常用于实验性策略或特殊部署。volume-config:拦截库与可执行文件的清单配置,是实现 CUDA 拦截的核心参数。docker-endpoint:容器运行时通信入口,用于检查容器状态与设备占用。query-port:统计与监控服务端口。kubeconfig:集群鉴权配置。standalone:独立运行模式,便于调试。sample-period:采样周期,决定指标更新频率。node-labels:自动打标签,便于调度器识别 GPU 节点。hostname-override:保证只对本节点 Pod 生效。virtual-manager-path:容器级 vGPU 运行目录。device-plugin-path:device plugin socket 目录。checkpoint-path:保存分配状态与恢复信息。share-mode:是否启用共享模式,直接影响虚拟化能力。allocation-check-period:周期性检查与修复策略。incluster-mode:集群内运行标识。
这组参数覆盖了"发现、分配、监控、恢复"全链路,在实际部署中应重点关注 volume-config 与 checkpoint-path 的正确性。
八、启动流程总览:从 Run 到 Register
gpu-manager 的启动流程可以抽象为以下步骤:
- 初始化并运行
VolumeManager,镜像并替换驱动与 CUDA 库; - 启动 watchdog,建立 Pod 状态缓存与监听;
- 自动为 GPU 节点打标签;
- 启动
VirtualManager管理 vGPU 生命周期; - 进行 GPU 拓扑感知与构建;
- 初始化分配器(Allocator);
- 启动 vcuda、vmemory、display、metrics 等服务;
- 注册 device plugin 到 kubelet。
这条链路中最关键的工程步骤是"驱动镜像 + CUDA 拦截"与"拓扑感知 + 分配决策"。前者决定虚拟化是否成功,后者决定性能是否稳定。
为了更直观理解启动过程,可以用一个简化流程图表示:
+-----------+ +----------------+ +-------------------+
| Run() | -> | VolumeManager | -> | Watchdog/Labeling |
+-----------+ +----------------+ +-------------------+
| |
v v
+------------------+ +-------------------+
| Topology Discover| -> | Allocator Init |
+------------------+ +-------------------+
|
v
+------------------------+
| Start gRPC Services |
| (vcuda/vmemory/metrics)|
+------------------------+
|
v
+------------------------+
| Register to kubelet |
+------------------------+
一个简化的启动伪代码如下,强调核心步骤顺序:
func (m *managerImpl) Run() error {
if err := m.volumeManager.Run(); err != nil {
return err
}
m.watchdog.Start()
m.labeler.Apply()
tree := m.discoverGPUTopology()
m.allocator = m.initAllocator(tree)
m.startServices() // vcuda/vmemory/display/metrics
return m.RegisterToKubelet()
}
九、VolumeManager:拦截 CUDA 调用的工程入口
VolumeManager 的核心任务是构建一个"被控制的驱动视图"。它会根据 volume-config 里指定的库和可执行文件,做以下事情:
- 使用
ldcache查找动态库路径; - 使用系统
which查找可执行文件; - 将目标文件复制或硬链接到
/etc/gpu-manager/vdriver目录; - 记录
libcuda.so的版本; - 定位
libcuda-control.so,作为拦截库; - 替换
libcuda.so与libnvidia-ml.so软链接,强制流量进入拦截层。
这种设计的核心价值在于"对系统无侵入":gpu-manager 不直接修改系统驱动,而是构建自己的"镜像路径",并在容器环境中覆盖 LD_LIBRARY_PATH,让容器加载的是虚拟化后的库。
从工程角度看,这种方案有三点好处:
- 可回滚:卸载 plugin 即可回到原始驱动路径;
- 兼容性好:无需内核补丁或特殊硬件;
- 易治理:拦截策略集中在一个目录,易于检查与审计。
以下是 VolumeManager 的简化逻辑示意,展示如何查找库并执行镜像:
func (vm *VolumeManager) Run() error {
cache, err := ldcache.Open()
if err != nil {
return err
}
defer cache.Close()
vols := make(VolumeMap)
for _, cfg := range vm.Config {
vol := &Volume{Path: path.Join(cfg.BasePath, cfg.Name)}
for t, c := range cfg.Components {
switch t {
case "binaries":
bins, _ := which(c...)
vol.dirs = append(vol.dirs, volumeDir{binDir, bins})
case "libraries":
libs32, libs64 := cache.Lookup(c...)
vol.dirs = append(vol.dirs, volumeDir{lib32Dir, libs32})
vol.dirs = append(vol.dirs, volumeDir{lib64Dir, libs64})
}
}
vols[cfg.Name] = vol
}
return vm.mirror(vols)
}
十、镜像与替换:为什么不是简单复制
VolumeManager 并不是简单复制文件,它会考虑动态库的 soname 与软链接结构。动态库的真实文件名(如 libcuda.so.525.60)和 soname(如 libcuda.so.1)往往不同,如果缺少软链接,应用会在运行时找不到库。
因此,mirrorFiles 在复制库的同时会创建 soname 软链接,并在共享模式下主动移除 libcuda.so 与 libnvidia-ml.so 的软链接,改为指向拦截库。这样做的工程意义是:
- 保证容器运行时能正确加载库;
- 让 CUDA 调用入口被统一劫持;
- 避免应用绕过拦截层直接调用真实驱动。
黑名单机制(blacklisted)则用于排除不应被拦截的库,这在驱动兼容性处理上非常关键。
拦截替换的关键思路可以用下面的简化流程图表示:
App -> libcuda.so (vdriver) -> libcuda-control.so -> libcuda.so (origin)
对应的镜像替换逻辑可以抽象为以下伪代码:
func (vm *VolumeManager) mirrorFiles(driver, vpath, file string) error {
obj, err := elf.Open(file)
if err != nil {
return err
}
defer obj.Close()
if ok, _ := blacklisted(file, obj); ok {
return nil
}
dst := path.Join(vpath, path.Base(file))
_ = removeFile(dst)
if err := clone(file, dst); err != nil {
return err
}
soname, _ := obj.DynString(elf.DT_SONAME)
if len(soname) > 0 {
linkIfNotSameName(path.Base(file), path.Join(vpath, soname[0]))
}
if vm.share && driver == "nvidia" && strings.HasPrefix(soname[0], "libcuda.so") {
os.Remove(path.Join(vpath, soname[0]))
vm.cudaSoname[path.Join(vpath, soname[0])] = path.Join(vpath, soname[0])
}
return nil
}
十一、vGPU Library:拦截 CUDA 调用的核心
libcuda-control.so 是 vGPU Library 的核心产物。它的工作方式并不是"虚拟出一块新 GPU",而是拦截 CUDA API 调用,并在调用过程中进行资源限制、统计或代理。
常见的拦截策略包括:
- 对
cudaMalloc、cudaMemcpy等调用进行配额限制; - 对执行队列进行统计,以便估算计算占用;
- 对 GPU 上下文进行隔离,避免容器之间互相影响。
这种拦截方式的优点是无需修改应用代码,也无需硬件级支持,但它的风险在于兼容性:如果 CUDA API 版本变化或驱动行为变化,拦截层可能需要同步调整。
十二、拓扑感知:调度最优的关键
GPU 并不是一个"均匀资源"。它与 CPU 的拓扑关系、GPU 间的互联方式都会影响性能:
- PCIe 拓扑:跨 PCIe 交换机会增加延迟;
- NUMA 结构:跨 NUMA 访问显著增加内存延迟;
- NVLink:提供更高的 GPU-GPU 带宽,适合多卡训练;
- 同一 PCIe Root Complex:往往意味着更优的带宽路径。
gpu-manager 在启动时会构建 GPUTree,并在分配时尽量选择拓扑更优的组合。对于多卡训练任务来说,这一步会直接影响训练速度与稳定性。
十三、Allocator:从"可用"到"可优"的分配策略
Allocator 的核心职责是:在 GPU 资源可共享的前提下,找到最优分配方案。它在初始化时会:
- 加载内核模块(保证驱动正常);
- 初始化评估器(Evaluator);
- 加载扩展配置;
- 启动后台协程处理分配结果;
- 从 checkpoint 恢复已分配状态;
- 周期性检查异常分配。
Evaluator 的存在意味着分配策略可扩展。常见策略包括:
- 最小碎片优先:尽量减少 GPU 上的碎片化;
- 拓扑优先:优先选择拓扑路径更优的 GPU;
- 显存优先:优先保证显存需求充足;
- 均衡策略:在多个 GPU 间均摊负载。
实际部署中,往往需要结合业务类型选择策略。例如训练任务更关心拓扑与带宽,而推理任务更关心显存与上下文隔离。
十四、注册与 Allocate:与 kubelet 的真实交互
gpu-manager 的注册过程是与 kubelet socket 的 gRPC 通信。注册时会对 vcuda 与 vmemory 两类资源分别发起 Register 请求,并设置 PreStartRequired。这意味着 kubelet 在容器启动前会触发预启动流程,给插件准备资源注入的机会。
Allocate 调用是核心执行阶段,它通常涉及:
- 校验请求资源;
- 选择具体 GPU 设备或虚拟设备;
- 挂载必要的驱动路径与库路径;
- 注入环境变量与配置;
- 记录分配关系以便恢复。
如果 Allocate 失败,容器将无法启动。这一流程的稳定性直接决定 GPU 虚拟化平台的可靠性。
以下是 device plugin 注册与 Allocate 的简化代码示意,强调交互路径:
func (m *managerImpl) RegisterToKubelet() error {
socketFile := filepath.Join(m.config.DevicePluginPath, types.KubeletSocket)
conn, err := grpc.Dial(socketFile, grpc.WithInsecure(), grpc.WithBlock())
if err != nil {
return err
}
defer conn.Close()
client := pluginapi.NewRegistrationClient(conn)
for _, srv := range m.bundleServer {
req := &pluginapi.RegisterRequest{
Version: pluginapi.Version,
Endpoint: path.Base(srv.SocketName()),
ResourceName: srv.ResourceName(),
Options: &pluginapi.DevicePluginOptions{PreStartRequired: true},
}
if _, err := client.Register(context.Background(), req); err != nil {
return err
}
}
return nil
}
func (s *vcudaServer) Allocate(ctx context.Context, req *pluginapi.AllocateRequest) (*pluginapi.AllocateResponse, error) {
devices := s.pickDevices(req)
mounts := s.prepareMounts(devices)
envs := s.injectEnv(devices)
return buildAllocateResp(mounts, envs), nil
}
Allocate 的时序关系可以用简化流程图表示:
Pod Spec -> Scheduler -> kubelet -> device plugin Allocate
| |
v v
Mount vdriver Inject env/config
|
v
Start container
十五、checkpoint 与恢复:生产可用性的底座
如果 gpu-manager 重启,必须能够恢复之前的分配关系,否则会导致"资源丢失"或"重复分配"。因此,checkpoint 机制非常关键。
恢复过程通常包括:
- 从 checkpoint 文件读取历史分配状态;
- 通过 docker endpoint 查询仍在运行的容器;
- 对比并修复异常记录;
- 更新内部缓存状态。
生产环境中,建议将 checkpoint 放在稳定磁盘路径,避免容器重启或磁盘清理导致数据丢失。
十六、监控与运维:从"能用"到"可管"
gpu-manager 内置 metrics 服务,便于接入 Prometheus 进行监控。典型的监控指标包括:
- GPU 使用率(计算与显存);
- 虚拟资源分配量与实际占用;
- 失败分配次数;
- 运行中容器与 GPU 绑定关系。
建议的运维实践:
- 配置告警:分配失败率高、驱动异常、插件 socket 不可用;
- 定期审计:检查
vdriver目录与拦截库版本; - 灰度升级:驱动与拦截库升级应在部分节点先试运行。
十七、异常场景与风险边界
在真实环境中,以下问题较为常见:
-
驱动版本不匹配:
libcuda-control.so与系统驱动版本不一致,导致 CUDA 初始化失败。解决办法是确保拦截库与驱动版本同步升级。 -
容器绕过拦截:如果容器手动修改
LD_LIBRARY_PATH或挂载了自带的 CUDA 目录,可能绕过拦截层。需要在 Admission 阶段进行限制或审计。 -
device plugin socket 无权限:导致注册失败。应检查 kubelet 版本与 socket 目录权限。
-
分配缓存异常:断电或重启导致 checkpoint 损坏。建议增加备份或校验机制。
-
性能波动:共享模式下多个任务竞争 GPU,可能出现抖动。需结合配额策略与队列优先级管理。
十八、部署实践:一份可操作的清单
下面是一份偏工程化的部署清单,供实际落地参考:
- 节点准备
- 确保驱动版本一致;
- CUDA 工具链与运行库完整;
- 关闭或记录可能冲突的 GPU 监控组件。
- 配置准备
volume-config指向正确的库与可执行文件;checkpoint-path放在稳定目录;sample-period根据业务需求设置。
- 部署方式
- DaemonSet 部署至 GPU 节点;
- nodeSelector 或 taint/toleration 做调度隔离。
- 验证步骤
- 检查 device plugin 注册是否成功;
- 运行简单 CUDA 容器验证库加载;
- 观察 metrics 是否正常输出。
十九、调度策略的工程化选择
在实际业务中,调度策略应与业务类型匹配:
- 训练场景:优先拓扑与带宽,保证多卡训练效率;
- 推理场景:优先显存与容器密度,提高单卡吞吐;
- 混合场景:需要隔离训练与推理任务,避免资源互相影响。
可考虑策略组合:
- 训练任务绑定高带宽拓扑;
- 推理任务在剩余卡上尽量填充;
- 高优先级任务预留 GPU 资源。
二十、性能与公平:共享模式的治理难题
共享模式的好处显著,但带来的问题是"公平性"。不同任务的 CUDA 调用方式和内核执行时间差异很大,单纯的显存配额并不能保证公平的计算资源分配。常见的治理手段包括:
- 结合队列系统限制任务并发数量;
- 在运行时增加调度层,对 GPU 使用进行排队;
- 对特定租户设置限速策略。
这是 GPU 虚拟化长期需要解决的难题之一,也是未来系统演进的重要方向。
二十一、未来演进方向
gpu-manager 代表的软件层虚拟化方案依然有许多可演进点:
- 更细粒度资源模型:如对 SM/Tensor Core 的控制;
- 动态分配与回收:基于实时负载弹性调整;
- 跨节点调度优化:结合全局调度器提高集群效率;
- 多维度 QoS:在吞吐、延迟、公平之间做系统级权衡。
这些方向的实现往往需要更深的驱动协同与调度系统支持,但从工程价值角度看十分值得投入。
二十二、运行期拦截的实现视角
从实现角度看,gpu-manager 的"虚拟化"并不等同于硬件层的分割,而是对用户态调用路径进行重定向。其核心是动态链接与加载过程:当容器内的程序调用 CUDA API 时,动态链接器会按 LD_LIBRARY_PATH、rpath、系统默认目录依次寻找对应的共享库。gpu-manager 将被拦截的库放到自己的镜像路径,并在容器内优先加载这些库,从而实现"拦截先于真实驱动"的效果。
这种拦截通常具备以下几类能力:
- 函数级代理:拦截
cudaMalloc、cudaFree、cuCtxCreate等关键调用,在调用前后记录状态,必要时进行配额判断。 - 设备选择重写:对
cudaSetDevice或设备枚举结果进行修改,让容器只看到"虚拟设备集合"。 - 限制策略注入:通过环境变量或共享内存,将资源配额、时间片策略传入拦截层。
对平台方而言,理解这一层非常重要,因为它决定了"资源限制是否可靠"。一旦用户容器能够绕开拦截库,系统就失去控制。因此工程上需要配合 Admission 规则、容器镜像治理、只读挂载等方式,确保拦截路径不可被随意修改。
二十三、性能评估与基准
在共享模式下,性能评估不能只看"GPU 使用率",还需要同时观察吞吐、延迟、抖动与公平性。推荐的评估方法包括:
-
单任务基准
在独占模式下跑基准模型,得到 baseline,记录吞吐与延迟。 -
多任务竞争
同时启动多个容器,观察吞吐下降比例、显存分配是否稳定、是否出现显存碎片。 -
拓扑敏感基准
多卡训练任务在不同 GPU 组合上运行,对比 NVLink 与 PCIe 拓扑差异带来的性能变化。 -
恢复与重启测试
模拟 gpu-manager 重启,检查 checkpoint 恢复是否可靠,以及任务是否继续正常执行。 -
极限配额测试
将显存配额设得极小,观察拦截层是否准确拒绝分配请求,避免容器 OOM 影响全局。
这些评估维度有助于区分"表面可用"和"工程可用"。只有在多任务、重启、异常情况下依然稳定,才算具备生产可用性。
二十四、排错与 FAQ
下面列出常见问题与排查思路,便于在现场快速定位:
-
问题:Pod 一直 Pending,资源无法调度
检查kubectl describe pod是否显示自定义资源不足;确认 device plugin 是否已注册成功,kubelet 侧是否识别到vcuda-core与vcuda-memory。 -
问题:Pod 启动后 CUDA 初始化失败
检查容器内LD_LIBRARY_PATH是否覆盖了 gpu-manager 的镜像目录;确认libcuda-control.so是否存在并与驱动版本匹配。 -
问题:分配后容器可见 GPU 数量不正确
检查 Allocate 逻辑是否成功写入设备过滤参数;确认虚拟设备映射是否正确。 -
问题:GPU 使用率异常偏高或偏低
查看 metrics 输出与容器内观测结果是否一致,排查是否存在拦截层采样失真或监控侧采集延迟。 -
问题:gpu-manager 重启后资源异常
检查checkpoint-path是否存在损坏或被清理;确认容器检查逻辑是否能正确恢复运行容器。
二十五、案例:训练与推理混部的调度策略示例
为了更直观理解 gpu-manager 在真实业务中的价值,下面给出一个简化案例。假设某团队同时运行两类业务:
- 离线训练任务:需要多卡并行,吞吐敏感,通常持续数小时;
- 在线推理服务:单卡多实例,延迟敏感,负载波动明显。
在传统"整卡独占"的模式下,二者难以共享资源,推理服务往往会占掉大量空闲算力。而在 gpu-manager 的共享模式下,可以通过资源请求与调度策略实现更合理的混部:
- 训练任务申请
vcuda-core=80、vcuda-memory=80Gi,并在调度器层面加上拓扑优先规则,确保多卡互联路径最优。 - 推理服务申请
vcuda-core=20、vcuda-memory=8Gi,并开启较短的监控采样周期,保证对负载波动快速响应。 - 当训练任务数量减少时,调度器可优先在同一张卡上填充更多推理实例,提高整体利用率。
这种策略下,关键收益包括:
- 训练任务仍保持高带宽拓扑优势;
- 推理服务在不影响训练任务的前提下提升密度;
- 运维侧可以通过 metrics 观察资源占用与碎片化趋势,提前做容量规划。
此类混部场景是 GPU 平台最常见的"价值兑现点",也是 gpu-manager 最容易体现收益的应用方式。
二十六、落地中的组织与流程建议
GPU 虚拟化不仅是技术问题,也是组织流程问题。很多平台在技术方案可行后仍然难以落地,原因通常在于资源申请、成本核算与运行治理没有形成闭环。以下是一些流程层面的建议:
-
资源申请标准化
为业务方提供明确的 GPU 资源申请模板,要求同时填写算力与显存需求,并给出预估时长或并发规模。这有助于调度器做更稳定的规划。 -
容量与成本可视化
将 GPU 使用率、显存占用率、虚拟分配比例等指标纳入业务侧可见的仪表盘,让申请者理解资源成本,从源头减少过度申请。 -
性能回归流程
驱动与拦截库升级需要统一的回归测试流程,避免一次升级影响全量任务。建议建立"金丝雀节点"用于验证。 -
故障归因机制
出现性能抖动或任务失败时,需要能快速区分是业务逻辑问题还是 GPU 虚拟化层导致的问题。可以通过基准任务与节点对比建立诊断流程。 -
跨团队协作
GPU 平台往往涉及基础设施、算法、平台、运维多个团队,建议设立统一的变更窗口与升级节奏,减少跨团队沟通成本。
通过流程配合,gpu-manager 的技术能力才能最大化发挥,不然会陷入"技术可行但业务不可用"的尴尬局面。
二十七、结语
gpu-manager 的意义远不止"启动一个 device plugin"。它在 Kubernetes 体系内提供了一套完整的 GPU 虚拟化工程路径:从驱动镜像与 CUDA 拦截到拓扑感知与分配策略,再到运行期恢复与监控治理。它让 GPU 平台从"设备管理"走向"资源治理"——当 GPU 能够被度量、拆分、调度和审计,企业就能在资源层面建立清晰的成本结构与性能边界。
如果要落地 gpu-manager,建议从小规模集群开始,选取一两个典型业务试点,通过基准任务验证性能与稳定性,再逐步扩大范围。对驱动版本、拦截库、监控链路建立长期维护机制,才能避免"短期可用、长期不可控"的风险。
最终目标不是"让更多 Pod 跑上 GPU",而是建立一个可预测、可治理、可持续的 GPU 资源市场。gpu-manager 提供的是基础设施能力,真正的价值来自它与调度策略、业务需求和运维流程的协同。
参考链接:
- https://ieeexplore.ieee.org/document/8672301
- CUDA Toolkit Documentation 12.4 Update 1 - https://docs.nvidia.com/cuda/index.html
- GPU虚拟化,算力隔离,和qGPU - https://zhuanlan.zhihu.com/p/377073683
- Multi-Process Service - https://docs.nvidia.com/deploy/mps/index.html
- MIG User Guide - https://docs.nvidia.com/datacenter/tesla/mig-user-guide/index.html
- GaiaGPU: Sharing GPUs in Container Clouds - https://ieeexplore.ieee.org/document/8672301
- tkestack/vcuda-controller - https://github.com/tkestack/vcuda-controller
- GPU容器共享技术cGPU - https://help.aliyun.com/zh/egs/what-is-cgpu
- 百度双引擎GPU虚拟化 - https://xie.infoq.cn/article/64df7b9a6606c139753658758
- NVIDIA open-gpu-kernel-modules - https://github.com/NVIDIA/open-gpu-kernel-modules